





Data Format
Multimodal Data
画像・テキスト・音声を統合したマルチモーダルAIデータセット作成。
最新のVision-Language Modelsに対応した
高品質アノテーションサービス。
最新のVision-Language Modelsに対応した
高品質アノテーションサービス。
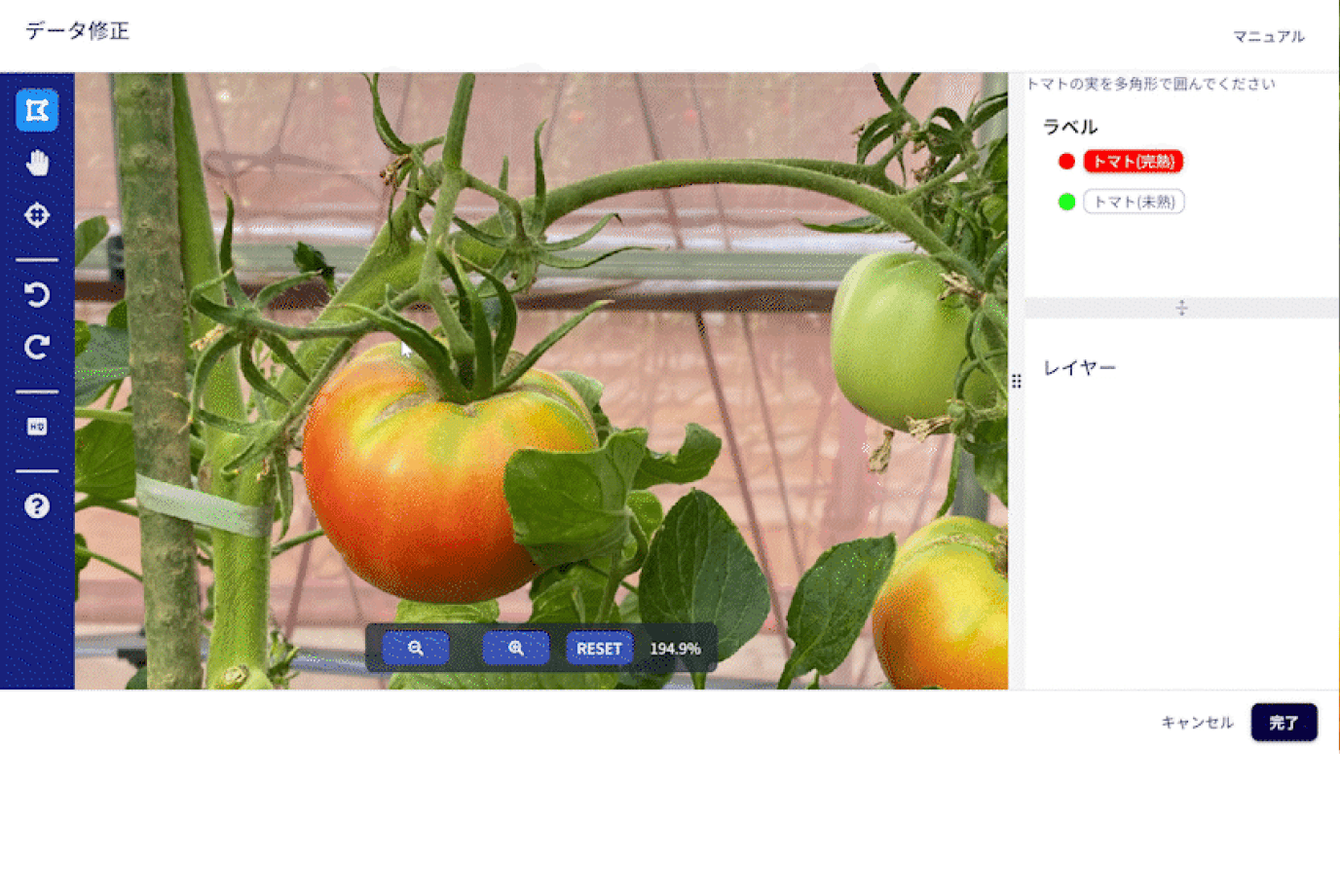
マルチモーダルAIは、画像・テキスト・音声などの異なるデータタイプを統合して処理する次世代AI技術です。単一データでは実現できない、より人間らしい理解と判断を可能にし、GPT-4V、Claude 3、Geminiなどの最先端モデルの中核技術として注目されています。

OpenAI製最新マルチモーダルモデル
Anthropic製最新高性能Vision Model
Google製最新マルチモーダルAI
最新Attention-Centric物体検出モデル
高精度物体検出・セグメンテーション
Meta製汎用セグメンテーションモデル
Meta製最新マルチモーダルLLM
画像-テキストマッチングモデル
Alibaba製マルチモーダルLLM
高品質な画像とキャプションのペアデータセット。Vision-Language Modelsのトレーニングに最適。
Visual Question Answering用データセット。画像に関する質問と回答のペア。
YOLO、Faster R-CNN等の物体検出モデル用アノテーション済みデータセット。
音声と映像の同期データセット。音声認識・話者認識と映像解析の統合学習用。
文書画像の理解・抽出用データセット。OCR・レイアウト解析・情報抽出に対応。
画像を含む複雑な指示の理解・実行用データセット。マルチステップタスクに対応。
上記以外にも、カスタムデータセットの作成を承っております
カスタムデータセットをUnlock new possibilities for your business with APTO's AI data.
Feel free to get started by requesting our materials.
